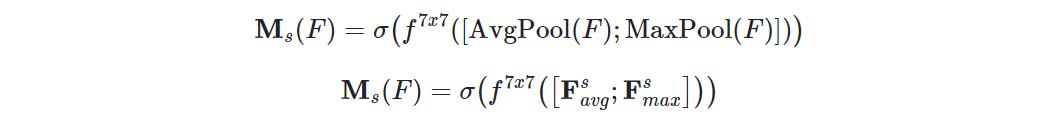Background:
The model’s backbone consists of RegNet model followed by BiFPN layers to have multi-level feature maps of the image. This technique helps in detection of smaller objects which are hard to detect in same-level feature maps because of the processing of the images through multiple convolutional layers. This post details the next step that comes with processing of feature maps with a sptial attention module.
After the RegNet + BiFPN backbone, the feature maps are passed into the spatial attention module to generate a map by utilizing the inter-spatial relationship of features. This is in contrast to the channel attention which focus on ‘which’ feature map to pay attention to. In comparison to that, the spatial attention module tells you ‘what’ to focus on in a feature map as chosen by the feature map. This is in contrast to the Anchors we discussed previously. The transformer architecture uses the query, key and value pairs to drive the feature maps that are most relevant for our purposes of object detection.
To generate the spatial attention, first step is to apply the average pooling and max pooling operation along the channel axis to two 2D maps i.e. one for average pooling and one for max pooling. Then, we use a conv layer to convolve the concatenated map to produce a 2D spatial attention map. In short, spatial attention is computed as: