Occupancy Networks:
Background:
The use and recreation of 3D spaces for certain computer vision applications has been extensively researched recently. Multiple different models have been proposed that work with different types of 3D inputs like point clouds and voxels to reconstruct a scene. However, each of the approach comes with drawbacks like memory inefficiency or complex implementation. During the research on occupancy networks, the researchers built a model that can
The key insight used by the researchers is that the 3D function can be approximated with a neural network. In essence, it is the same as a binary classification i.e. we are assigning a probability value to each 3D point about whether it is occupied or not. However, we are interested in the decision boundary that implicitly represents the object’s surface.
Whether we are using images, point clouds, or voxels to do a 3D reconstruction of an object, we must condition it on the input. For this purpose, we can use a simple functional equivalence: a function that takes an observation x E X as input and has a function p E R^3 to R as output can be equivalently described by a function that takes a pair (p,x) E R^3 x X as inputs and outputs a real number. This relationship is depicted in the equation below:
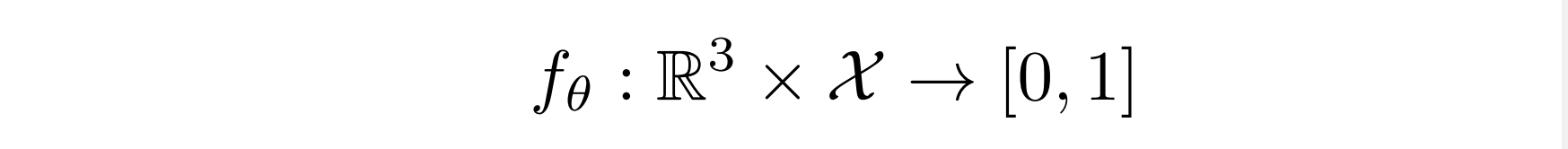
X is the condition i.e. encoding of an image, for example. R^3 is the 3d point we take in and we are outputting the occupancy probability about whether the object is occupied or not.
Now that we have a good idea of the intuition of the occupancy network, we can get into a bit more detail about using the occupancy networks for 3D reconstruction from 2D images.
Implicit representation which doesn’t require discretization. Instead of representing the 3D shape explicitly, we consider the object surface implicitly as a decision boundary of a non-linear classifier. The idea stems from a simple deduction. Instead of wanting to reason about the occupancy at a fixed discrete 3D location, we want to know the occupancy at every possible 3D point in a 3D space. The resulting function is the occupancy object of the 3D object:
The {0,1} is the probability of that 3D point being occupied. Network Architecture: Encoder: 2d image / point cloud, encoder produces a vector, maybe a 128-d vector. ResNet layers are conditioned on the encoder output. Pass in 3-d point/ Can pass in as many points as we can fit on the GPU. Fe into the network, processed jointly and we get one value i.e. the occupancy probability.
Classification loss: binary cross-entropy loss Want to get the label of whether the 3D point is occupied or not. Do it across the randomly sampled 3D points from the batch . Variational occupancy encoder - generative model. Trained in an unconditional way. Encoder takes a object representation. Predicts Q sign novel distribution Reconstruction. Because of the implicit representation. We need to extract the actual shape of the output. Multiresolution IsoSurface extraction: Start as regular grid of points - the grid is further divided into smaller patches to see exactly where the point exists. Only one point is occupied.
2D image + 3D Model -> texture field -> textured 3D model