Introduction:
It is a very different approach to view synthesis because with traditional CNNs, we use dataset to train the model and we make sure that we do not overfit on the data. However, with NeRFs, we overfit the model on the images taken from different angles of the same object to create a representing scene. This is accomplished by optimizing an underlying continuous volumetric scene function.
Non-convolutional network which takes in a radiance and an angle at each point (x, y, z) in a space and outputs density at those location. It outputs a single volume density and view-dependent RGB color.
Advantages:
With SIREN networks, it is a much better representation than a mesh vs. voxels.
Inputs:
- Coordinate system: x,y,z
- Pass in a position in the system i.e. 3D vector of the point
- Angle i.e. viewing direction.
Outputs:
- Color C - what color is at the particular location
- Density - The density represents the color whether something is at a certain pixel in the scene.
The weights of the neural networks learn what is in the scene and what density it is. The NN gives different results based on where you are in the image.
Steps:
- Pass camera rays through the scene to get the 3D points.
- Use the points along with their corresponding 2D viewing directions i.e. radiance and angle to produce an output of colors and densities.
- Using the classical volume rendering techniques to accumulate colors and densities into a 2D image.
Neural Radiance Field Scene representation
5D vector-valued function with input of 3D location = (x, y, z) along with a viewing direction (2D). Output is an emitted color c = (r, g, b) and volume density (1D).
Inputs:
The image pixels are processed using the ray tracers to get the (x, y, z) input values. The Ray Tracer implementation is explained in depth in the next post but essentially, the Ray Tracer works by sending a ray through a particular pixel in an image. Along the ray, multiple points are sampled to check the opacity at those locations. It is these (x, y, z) points along with their viewing directions that are passed to the MLP network.
Outputs:
The next question that comes up is how do we get the density with the ray tracing technique explained before. With a set of images, a loss can be calculated with what you have vs what to predict. The network is queried to see what exists at a particular pixel location. The network compares the image and the output to calculate the loss. Every pixel is acting as a ray, with the dataset consisting of every pixel in every image. Since the loss is differentiable, you can train the model. The model is over-fitted to the images of the object and the weights of the trained model are used for inference.
The method involved multiple different techniques:
- March camera rays through the scene to get (x, y, z) representations
- Use a NN to produce an output of colors and densities
- Use Volume rendering techniques to accumulate the colors and densities into 2D images.
Volume Rendering with Radiance Fields
The radiance field is the function that is used to train the neural network. Each pixel is treated as a ray and the model is trained so that it is able to predict what to see at each pixel location. Send a ray through the scene, integrate along that ray with a far bound and near bound. The model is trained to predict the color at the pixel location by the following formula:
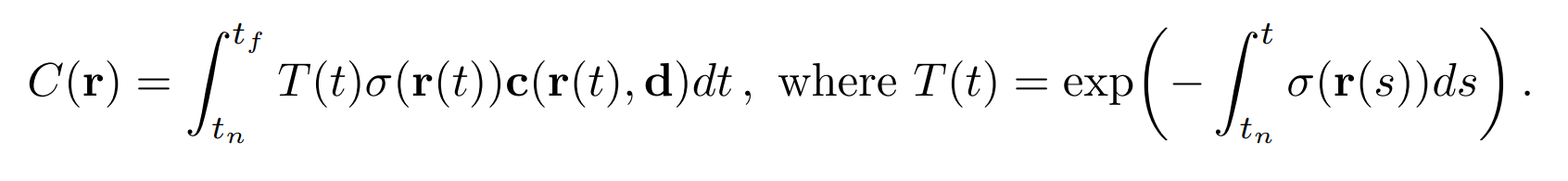
The integral refers to the integration from near bound to the far bound as the ray travels through the pixel. T(t) is the probability of empty space and it determined how much occludance is at that particular pixel location in the image. If the network determines there is something at the pixel location, the array adopts the color at that location. After that, T(t) is going to be small because T(t) is an inner integral. Once the color is adopted, the ray stop moving because there is obviously occludance there, so the value of T(t) is small.